

Use Structure In App Designer
This guide encompasses best practices and recommended architecture for building robust, production-quality apps.
This page assumes a basic familiarity with the Android Framework. If you are new to Android app development, check out our Developer guides to get started and learn more about the concepts mentioned in this guide.
If you're interested in app architecture, and would like to see the material in this guide from a Kotlin programming perspective, check out the Udacity course Developing Android Apps with Kotlin.
Mobile app user experiences
In the majority of cases, desktop apps have a single entry point from a desktop or program launcher, then run as a single, monolithic process. Android apps, on the other hand, have a much more complex structure. A typical Android app contains multiple app components, including activities, fragments, services, content providers, and broadcast receivers.
You declare most of these app components in your app manifest. The Android OS then uses this file to decide how to integrate your app into the device's overall user experience. Given that a properly-written Android app contains multiple components and that users often interact with multiple apps in a short period of time, apps need to adapt to different kinds of user-driven workflows and tasks.
For example, consider what happens when you share a photo in your favorite social networking app:
- The app triggers a camera intent. The Android OS then launches a camera app to handle the request. At this point, the user has left the social networking app, but their experience is still seamless.
- The camera app might trigger other intents, like launching the file chooser, which may launch yet another app.
- Eventually, the user returns to the social networking app and shares the photo.
At any point during the process, the user could be interrupted by a phone call or notification. After acting upon this interruption, the user expects to be able to return to, and resume, this photo-sharing process. This app-hopping behavior is common on mobile devices, so your app must handle these flows correctly.
Keep in mind that mobile devices are also resource-constrained, so at any time, the operating system might kill some app processes to make room for new ones.
Given the conditions of this environment, it's possible for your app components to be launched individually and out-of-order, and the operating system or user can destroy them at any time. Because these events aren't under your control, you shouldn't store any app data or state in your app components, and your app components shouldn't depend on each other.
Common architectural principles
If you shouldn't use app components to store app data and state, how should you design your app?
Separation of concerns
The most important principle to follow is separation of concerns. It's a common mistake to write all your code in an Activity or a Fragment. These UI-based classes should only contain logic that handles UI and operating system interactions. By keeping these classes as lean as possible, you can avoid many lifecycle-related problems.
Keep in mind that you don't own implementations of Activity and Fragment; rather, these are just glue classes that represent the contract between the Android OS and your app. The OS can destroy them at any time based on user interactions or because of system conditions like low memory. To provide a satisfactory user experience and a more manageable app maintenance experience, it's best to minimize your dependency on them.
Drive UI from a model
Another important principle is that you should drive your UI from a model, preferably a persistent model. Models are components that are responsible for handling the data for an app. They're independent from the View objects and app components in your app, so they're unaffected by the app's lifecycle and the associated concerns.
Persistence is ideal for the following reasons:
- Your users don't lose data if the Android OS destroys your app to free up resources.
- Your app continues to work in cases when a network connection is flaky or not available.
By basing your app on model classes with the well-defined responsibility of managing the data, your app is more testable and consistent.
Recommended app architecture
In this section, we demonstrate how to structure an app using Architecture Components by working through an end-to-end use case.
Imagine we're building a UI that shows a user profile. We use a private backend and a REST API to fetch the data for a given profile.
Overview
To start, consider the following diagram, which shows how all the modules should interact with one another after designing the app:
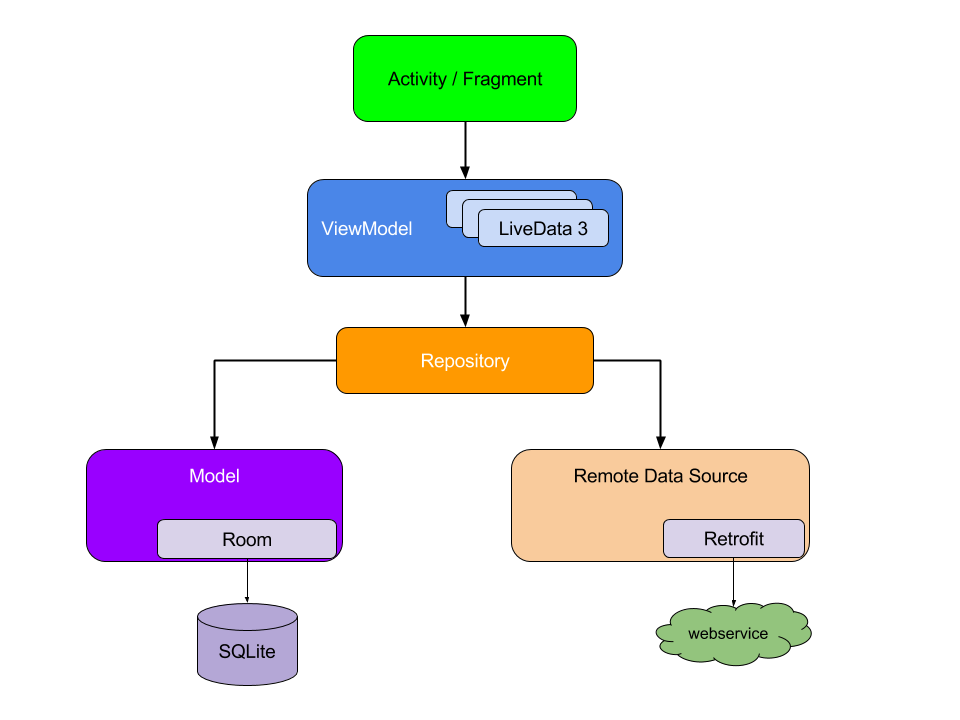
Notice that each component depends only on the component one level below it. For example, activities and fragments depend only on a view model. The repository is the only class that depends on multiple other classes; in this example, the repository depends on a persistent data model and a remote backend data source.
This design creates a consistent and pleasant user experience. Regardless of whether the user comes back to the app several minutes after they've last closed it or several days later, they instantly see a user's information that the app persists locally. If this data is stale, the app's repository module starts updating the data in the background.
Build the user interface
The UI consists of a fragment, UserProfileFragment, and its corresponding layout file, user_profile_layout.xml.
To drive the UI, our data model needs to hold the following data elements:
- User ID: The identifier for the user. It's best to pass this information into the fragment using the fragment arguments. If the Android OS destroys our process, this information is preserved, so the ID is available the next time our app is restarted.
- User object: A data class that holds details about the user.
We use a UserProfileViewModel, based on the ViewModel architecture component, to keep this information.
A
ViewModelobject provides the data for a specific UI component, such as a fragment or activity, and contains data-handling business logic to communicate with the model. For example, theViewModelcan call other components to load the data, and it can forward user requests to modify the data. TheViewModeldoesn't know about UI components, so it isn't affected by configuration changes, such as recreating an activity when rotating the device.
We've now defined the following files:
-
user_profile.xml: The UI layout definition for the screen. -
UserProfileFragment: The UI controller that displays the data. -
UserProfileViewModel: The class that prepares the data for viewing in theUserProfileFragmentand reacts to user interactions.
The following code snippets show the starting contents for these files. (The layout file is omitted for simplicity.)
UserProfileViewModel
class UserProfileViewModel : ViewModel() { val userId : String = TODO() val user : User = TODO() } UserProfileFragment
class UserProfileFragment : Fragment() { // To use the viewModels() extension function, include // "androidx.fragment:fragment-ktx:latest-version" in your app // module's build.gradle file. private val viewModel: UserProfileViewModel by viewModels() override fun onCreateView( inflater: LayoutInflater, container: ViewGroup?, savedInstanceState: Bundle? ): View { return inflater.inflate(R.layout.main_fragment, container, false) } } Now that we have these code modules, how do we connect them? After all, when the user field is set in the UserProfileViewModel class, we need a way to inform the UI.
To obtain the user, our ViewModel needs to access the Fragment arguments. We can either pass them from the Fragment, or better, using the SavedState module, we can make our ViewModel read the argument directly:
// UserProfileViewModel class UserProfileViewModel( savedStateHandle: SavedStateHandle ) : ViewModel() { val userId : String = savedStateHandle["uid"] ?: throw IllegalArgumentException("missing user id") val user : User = TODO() } // UserProfileFragment private val viewModel: UserProfileViewModel by viewModels( factoryProducer = { SavedStateVMFactory(this) } ... ) Now we need to inform our Fragment when the user object is obtained. This is where the LiveData architecture component comes in.
LiveData is an observable data holder. Other components in your app can monitor changes to objects using this holder without creating explicit and rigid dependency paths between them. The LiveData component also respects the lifecycle state of your app's components—such as activities, fragments, and services—and includes cleanup logic to prevent object leaking and excessive memory consumption.
To incorporate the LiveData component into our app, we change the field type in the UserProfileViewModel to LiveData<User>. Now, the UserProfileFragment is informed when the data is updated. Furthermore, because this LiveData field is lifecycle aware, it automatically cleans up references after they're no longer needed.
UserProfileViewModel
class UserProfileViewModel( savedStateHandle: SavedStateHandle ) : ViewModel() { val userId : String = savedStateHandle["uid"] ?: throw IllegalArgumentException("missing user id") val user : LiveData<User> = TODO() } Now we modify UserProfileFragment to observe the data and update the UI:
UserProfileFragment
override fun onViewCreated(view: View, savedInstanceState: Bundle?) { super.onViewCreated(view, savedInstanceState) viewModel.user.observe(viewLifecycleOwner) { // update UI } } Every time the user profile data is updated, the onChanged() callback is invoked, and the UI is refreshed.
If you're familiar with other libraries where observable callbacks are used, you might have realized that we didn't override the fragment's onStop() method to stop observing the data. This step isn't necessary with LiveData because it's lifecycle aware, which means it doesn't invoke the onChanged() callback unless the fragment is in an active state; that is, it has received onStart() but hasn't yet received onStop()). LiveData also automatically removes the observer when the fragment's onDestroy() method is called.
We also didn't add any logic to handle configuration changes, such as the user rotating the device's screen. The UserProfileViewModel is automatically restored when the configuration changes, so as soon as the new fragment is created, it receives the same instance of ViewModel, and the callback is invoked immediately using the current data. Given that ViewModel objects are intended to outlast the corresponding View objects that they update, you shouldn't include direct references to View objects within your implementation of ViewModel. For more information about the lifetime of a ViewModel corresponds to the lifecycle of UI components, see The lifecycle of a ViewModel.
Fetch data
Now that we've used LiveData to connect the UserProfileViewModel to the UserProfileFragment, how can we fetch the user profile data?
For this example, we assume that our backend provides a REST API. We use the Retrofit library to access our backend, though you are free to use a different library that serves the same purpose.
Here's our definition of Webservice that communicates with our backend:
Webservice
interface Webservice { /** * @GET declares an HTTP GET request * @Path("user") annotation on the userId parameter marks it as a * replacement for the {user} placeholder in the @GET path */ @GET("/users/{user}") suspend fun getUser(@Path("user") userId: String): User } A first idea for implementing the ViewModel might involve directly calling the Webservice to fetch the data and assign this data to our LiveData object. This design works, but by using it, our app becomes more and more difficult to maintain as it grows. It gives too much responsibility to the UserProfileViewModel class, which violates the separation of concerns principle. Additionally, the scope of a ViewModel is tied to an Activity or Fragment lifecycle, which means that the data from the Webservice is lost when the associated UI object's lifecycle ends. This behavior creates an undesirable user experience.
Instead, our ViewModel delegates the data-fetching process to a new module, a repository.
Repository modules handle data operations. They provide a clean API so that the rest of the app can retrieve this data easily. They know where to get the data from and what API calls to make when data is updated. You can consider repositories to be mediators between different data sources, such as persistent models, web services, and caches.
Our UserRepository class, shown in the following code snippet, uses an instance of WebService to fetch a user's data:
UserRepository
class UserRepository { private val webservice: Webservice = TODO() // ... suspend fun getUser(userId: String) = // This isn't an optimal implementation because it doesn't take into // account caching. We'll look at how to improve upon this in the next // sections. webservice.getUser(userId) } Even though the repository module looks unnecessary, it serves an important purpose: it abstracts the data sources from the rest of the app. Now, our UserProfileViewModel doesn't know how the data is fetched, so we can provide the view model with data obtained from several different data-fetching implementations.
Manage dependencies between components
The UserRepository class above needs an instance of Webservice to fetch the user's data. It could simply create the instance, but to do that, it also needs to know the dependencies of the Webservice class. Additionally,UserRepository is probably not the only class that needs a Webservice. This situation requires us to duplicate code, as each class that needs a reference to Webservice needs to know how to construct it and its dependencies. If each class creates a new WebService, our app could become very resource heavy.
You can use the following design patterns to address this problem:
- Dependency injection (DI): Dependency injection allows classes to define their dependencies without constructing them. At runtime, another class is responsible for providing these dependencies.
- Service locator: The service locator pattern provides a registry where classes can obtain their dependencies instead of constructing them.
These patterns allow you to scale your code because they provide clear patterns for managing dependencies without duplicating code or adding complexity. Furthermore, these patterns allow you to quickly switch between test and production data-fetching implementations.
We recommend following dependency injection patterns and using the Hilt library in Android apps. Hilt automatically constructs objects by walking the dependency tree, provides compile-time guarantees on dependencies, and creates dependency containers for Android framework classes.
Our example app uses Hilt to manage the Webservice object's dependencies.
Connect ViewModel and the repository
Now, we modify our UserProfileViewModel to use the UserRepository object:
UserProfileViewModel
@HiltViewModel class UserProfileViewModel @Inject constructor( savedStateHandle: SavedStateHandle, userRepository: UserRepository ) : ViewModel() { val userId: String = savedStateHandle["uid"] ?: throw IllegalArgumentException("missing user id") private val _user = MutableLiveData<User>() val user: LiveData<User> = _user init { viewModelScope.launch { _user.value = userRepository.getUser(userId) } } } Cache data
The UserRepository implementation abstracts the call to the Webservice object, but because it relies on only one data source, it's not very flexible.
The key problem with the UserRepository implementation is that after it fetches data from our backend, it doesn't store that data anywhere. Therefore, if the user leaves the UserProfileFragment, then returns to it, our app must re-fetch the data, even if it hasn't changed.
This design is suboptimal for the following reasons:
- It wastes valuable network bandwidth.
- It forces the user to wait for the new query to complete.
To address these shortcomings, we add a new data source to our UserRepository, which caches the User objects in memory:
UserRepository
// @Inject tells Hilt how to create instances of this type // and the dependencies it has. class UserRepository @Inject constructor( private val webservice: Webservice, // Simple in-memory cache. Details omitted for brevity. private val userCache: UserCache ) { suspend fun getUser(userId: String): User { val cached: User = userCache.get(userId) if (cached != null) { return cached } // This implementation is still suboptimal but better than before. // A complete implementation also handles error cases. val freshUser = webservice.getUser(userId) userCache.put(userId, freshUser) return freshUser } } Persist data
Using our current implementation, if the user rotates the device or leaves and immediately returns to the app, the existing UI becomes visible instantly because the repository retrieves data from our in-memory cache.
However, what happens if the user leaves the app and comes back hours later, after the Android OS has killed the process? By relying on our current implementation in this situation, we need to fetch the data again from the network. This refetching process isn't just a bad user experience; it's also wasteful because it consumes valuable mobile data.
You could fix this issue by caching the web requests, but that creates a key new problem: What happens if the same user data shows up from another type of request, such as fetching a list of friends? The app would show inconsistent data, which is confusing at best. For example, our app might show two different versions of the same user's data if the user made the list-of-friends request and the single-user request at different times. Our app would need to figure out how to merge this inconsistent data.
The proper way to handle this situation is to use a persistent model. This is where the Room persistence library comes to the rescue.
Room is an object-mapping library that provides local data persistence with minimal boilerplate code. At compile time, it validates each query against your data schema, so broken SQL queries result in compile-time errors instead of runtime failures. Room abstracts away some of the underlying implementation details of working with raw SQL tables and queries. It also allows you to observe changes to the database's data, including collections and join queries, exposing such changes using LiveData objects. It even explicitly defines execution constraints that address common threading issues, such as accessing storage on the main thread.
To use Room, we need to define our local schema. First, we add the @Entity annotation to our User data model class and a @PrimaryKey annotation to the class's id field. These annotations mark User as a table in our database and id as the table's primary key:
User
@Entity data class User( @PrimaryKey private val id: String, private val name: String, private val lastName: String ) Then, we create a database class by implementing RoomDatabase for our app:
UserDatabase
@Database(entities = [User::class], version = 1) abstract class UserDatabase : RoomDatabase() Notice that UserDatabase is abstract. Room automatically provides an implementation of it. For details, see the Room documentation.
We now need a way to insert user data into the database. For this task, we create a data access object (DAO).
UserDao
@Dao interface UserDao { @Insert(onConflict = REPLACE) fun save(user: User) @Query("SELECT * FROM user WHERE id = :userId") fun load(userId: String): Flow<User> } Notice that the load method returns an object of type Flow<User>. Using Flow with Room allows you to get live updates. This means that every time there's a change in the user table, a new User will be emitted.
With our UserDao class defined, we then reference the DAO from our database class:
UserDatabase
@Database(entities = [User::class], version = 1) abstract class UserDatabase : RoomDatabase() { abstract fun userDao(): UserDao } Now we can modify our UserRepository to incorporate the Room data source:
class UserRepository @Inject constructor( private val webservice: Webservice, // Simple in-memory cache. Details omitted for brevity. private val executor: Executor, private val userDao: UserDao ) { fun getUser(userId: String): Flow<User> { refreshUser(userId) // Returns a Flow object directly from the database. return userDao.load(userId) } private suspend fun refreshUser(userId: String) { // Check if user data was fetched recently. val userExists = userDao.hasUser(FRESH_TIMEOUT) if (!userExists) { // Refreshes the data. val response = webservice.getUser(userId) // Check for errors here. // Updates the database. Since `userDao.load()` returns an object of // `Flow<User>`, a new `User` object is emitted every time there's a // change in the `User` table. userDao.save(response.body()!!) } } companion object { val FRESH_TIMEOUT = TimeUnit.DAYS.toMillis(1) } } Now that getUser returns an object of Flow<User>, you need to update UserProfileViewModel to handle the new return type of Flow<User>:
@HiltViewModel class UserProfileViewModel @Inject constructor( savedStateHandle: SavedStateHandle, userRepository: UserRepository ) : ViewModel() { val userId : String = savedStateHandle["uid"] ?: throw IllegalArgumentException("missing user id") // asLiveData() is part of lifecycle-livedata-ktx // https://developer.android.com/kotlin/ktx#livedata val user = userRepository.getUser(userId).asLiveData() } Notice that even though you changed where the data comes from in UserRepository, you didn't need to change UserProfileFragment. This small-scoped update demonstrates the flexibility that this app architecture provides. It's also great for testing, because you can provide a mock instance of UserRepository and test your production UserProfileViewModel at the same time.
If users wait a few days before returning to an app that uses this architecture, it's likely that they'll see out-of-date information until the repository can fetch updated information. Depending on your use case, you may not want to show this out-of-date information. Instead, you can display placeholder data, which shows example values and indicates that your app is currently fetching and loading up-to-date information.
Single source of truth
It's common for different REST API endpoints to return the same data. For example, if our backend has another endpoint that returns a list of friends, the same user object could come from two different API endpoints, maybe even using different levels of granularity. If the UserRepository were to return the response from the Webservice request as-is, without checking for consistency, our UIs could show confusing information because the version and format of data from the repository would depend on the endpoint most recently called.
For this reason, our UserRepository implementation saves web service responses into the database. Changes to the database then trigger callbacks on active LiveData objects. Using this model, the database serves as the single source of truth, and other parts of the app access it using our UserRepository. Regardless of whether you use a disk cache, we recommend that your repository designate a data source as the single source of truth for the rest of your app.
Show in-progress operations
In some use cases, such as pull-to-refresh, it's important for the UI to show the user that there's currently a network operation in progress. It's good practice to separate the UI action from the actual data because the data might be updated for various reasons. For example, if we fetched a list of friends, the same user might be fetched again programmatically, triggering a LiveData<User> update. From the UI's perspective, the fact that there's a request in flight is just another data point, similar to any other piece of data in the User object itself.
We can use one of the following strategies to display a consistent data-updating status in the UI, regardless of where the request to update the data came from:
- Change
getUser()to return an object of typeLiveData. This object would include the status of the network operation.
For an example, see theNetworkBoundResourceimplementation in the android-architecture-components GitHub project. - Provide another public function in the
UserRepositoryclass that can return the refresh status of theUser. This option is better if you want to show the network status in your UI only when the data-fetching process originated from an explicit user action, such as pull-to-refresh.
Test each component
In the separation of concerns section, we mentioned that one key benefit of following this principle is testability.
The following list shows how to test each code module from our extended example:
- User interface and interactions: Use an Android UI instrumentation test. The best way to create this test is to use the Espresso library. You can create the fragment and provide it a mock
UserProfileViewModel. Because the fragment communicates only with theUserProfileViewModel, mocking this one class is sufficient to fully test your app's UI. - ViewModel: You can test the
UserProfileViewModelclass using a JUnit test. You only need to mock one class,UserRepository. - UserRepository: You can test the
UserRepositoryusing a JUnit test, as well. You need to mock theWebserviceand theUserDao. In these tests, verify the following behavior:- The repository makes the correct web service calls.
- The repository saves results into the database.
- The repository doesn't make unnecessary requests if the data is cached and up to date.
- Because both
WebserviceandUserDaoare interfaces, you can mock them or create fake implementations for more complex test cases. -
UserDao: Test DAO classes using instrumentation tests. Because these instrumentation tests don't require any UI components, they run quickly. For each test, create an in-memory database to ensure that the test doesn't have any side effects, such as changing the database files on disk.
Caution:Room allows specifying the database implementation, so it's possible to test your DAO by providing the JUnit implementation of
SupportSQLiteOpenHelper. This approach isn't recommended, however, because the SQLite version running on the device might differ from the SQLite version on your development machine. -
Webservice: In these tests, avoid making network calls to your backend. It's important for all tests, especially web-based ones, to be independent from the outside world. Several libraries, including MockWebServer, can help you create a fake local server for these tests.
-
Testing Artifacts: Architecture Components provides a maven artifact to control its background threads. The
androidx.arch.core:core-testingartifact contains the following JUnit rules:-
InstantTaskExecutorRule: Use this rule to instantly execute any background operation on the calling thread. -
CountingTaskExecutorRule: Use this rule to wait on background operations of Architecture Components. You can also associate this rule with Espresso as an idling resource.
-
Best practices
Programming is a creative field, and building Android apps isn't an exception. There are many ways to solve a problem, be it communicating data between multiple activities or fragments, retrieving remote data and persisting it locally for offline mode, or any number of other common scenarios that nontrivial apps encounter.
Although the following recommendations aren't mandatory, it has been our experience that following them makes your code base more robust, testable, and maintainable in the long run:
Avoid designating your app's entry points—such as activities, services, and broadcast receivers—as sources of data.
Instead, they should only coordinate with other components to retrieve the subset of data that is relevant to that entry point. Each app component is rather short-lived, depending on the user's interaction with their device and the overall current health of the system.
Create well-defined boundaries of responsibility between various modules of your app.
For example, don't spread the code that loads data from the network across multiple classes or packages in your code base. Similarly, don't define multiple unrelated responsibilities—such as data caching and data binding—into the same class.
Expose as little as possible from each module.
Don't be tempted to create "just that one" shortcut that exposes an internal implementation detail from one module. You might gain a bit of time in the short term, but you then incur technical debt many times over as your codebase evolves.
Consider how to make each module testable in isolation.
For example, having a well-defined API for fetching data from the network makes it easier to test the module that persists that data in a local database. If, instead, you mix the logic from these two modules in one place, or distribute your networking code across your entire code base, it becomes much more difficult—if not impossible—to test.
Focus on the unique core of your app so it stands out from other apps.
Don't reinvent the wheel by writing the same boilerplate code again and again. Instead, focus your time and energy on what makes your app unique, and let the Android Architecture Components and other recommended libraries handle the repetitive boilerplate.
Persist as much relevant and fresh data as possible.
That way, users can enjoy your app's functionality even when their device is in offline mode. Remember that not all of your users enjoy constant, high-speed connectivity.
Assign one data source to be the single source of truth.
Whenever your app needs to access this piece of data, it should always originate from this single source of truth.
Addendum: exposing network status
In the recommended app architecture section above, we omitted network error and loading states to keep the code snippets simple.
This section demonstrates how to expose network status using a Resource class that encapsulate both the data and its state.
The following code snippet provides a sample implementation of Resource:
Resource
// A generic class that contains data and status about loading this data. sealed class Resource<T>( val data: T? = null, val message: String? = null ) { class Success<T>(data: T) : Resource<T>(data) class Loading<T>(data: T? = null) : Resource<T>(data) class Error<T>(message: String, data: T? = null) : Resource<T>(data, message) } Because it's common to load data from the network while showing the disk copy of that data, it's good to create a helper class that you can reuse in multiple places. For this example, we create a class called NetworkBoundResource.
The following diagram shows the decision tree for NetworkBoundResource:
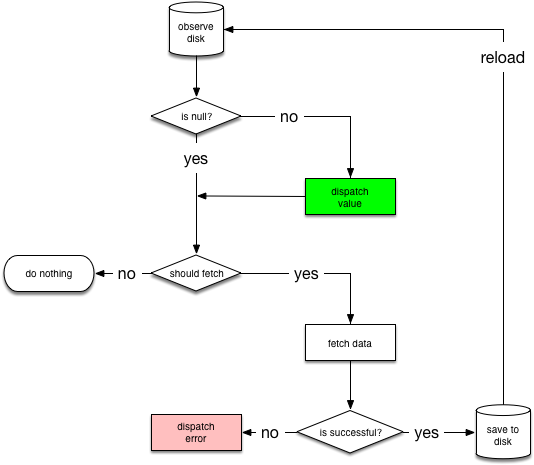
It starts by observing the database for the resource. When the entry is loaded from the database for the first time, NetworkBoundResource checks whether the result is good enough to be dispatched or that it should be re-fetched from the network. Note that both of these situations can happen at the same time, given that you probably want to show cached data while updating it from the network.
If the network call completes successfully, it saves the response into the database and re-initializes the stream. If network request fails, the NetworkBoundResource dispatches a failure directly.
Note: After saving new data to disk, we re-initialize the stream from the database. We usually don't need to do that, however, because the database itself happens to dispatch the change.
Keep in mind that relying on the database to dispatch the change involves relying on the associated side effects, which isn't good because undefined behavior from these side effects could occur if the database ends up not dispatching changes because the data hasn't changed.
Also, don't dispatch the result that arrived from the network because that would violate the single source of truth principle. After all, maybe the database includes triggers that change data values during a "save" operation. Similarly, don't dispatch `SUCCESS` without the new data, because then the client receives the wrong version of the data.
The following code snippet shows the public API provided by NetworkBoundResource class for its subclasses:
NetworkBoundResource.kt
// ResultType: Type for the Resource data. // RequestType: Type for the API response. abstract class NetworkBoundResource<ResultType, RequestType> { // Called to save the result of the API response into the database @WorkerThread protected abstract suspend fun saveCallResult(item: RequestType) // Called with the data in the database to decide whether to fetch // potentially updated data from the network. @MainThread protected abstract fun shouldFetch(data: ResultType?): Boolean // Called to get the cached data from the database. @MainThread protected abstract suspend fun loadFromDb(): Flow<ResultType> // Called to create the API call. @MainThread protected abstract fun createCall(): Flow<ApiResponse<RequestType>> // Called when the fetch fails. The child class may want to reset components // like rate limiter. protected open fun onFetchFailed() {} } Note these important details about the class's definition:
- It defines two type parameters,
ResultTypeandRequestType, because the data type returned from the API might not match the data type used locally. - It uses a class called
ApiResponsefor network requests.ApiResponseis a simple wrapper around theRetrofit2.Callclass that convert responses to instances ofLiveData.
The full implementation of the NetworkBoundResource class appears as part of the android-architecture-components GitHub project.
After creating the NetworkBoundResource, we can use it to write our disk- and network-bound implementations of User in the UserRepository class:
UserRepository
class UserRepository @Inject constructor( private val webservice: Webservice, private val userDao: UserDao ) { fun getUser(userId: String) = object : NetworkBoundResource<User, User>() { override suspend fun saveCallResult(item: User) { userDao.save(item) } override fun shouldFetch(data: User?): Boolean { return rateLimiter.canFetch(userId) && (data == null || !isFresh(data)) } override suspend fun loadFromDb(): Flow<User> { return userDao.load(userId) } override fun createCall(): Flow<ApiResponse<User>> { return webservice.getUser(userId) } } } Use Structure In App Designer
Source: https://developer.android.com/jetpack/guide
Posted by: mccoypaten1955.blogspot.com
0 Response to "Use Structure In App Designer"
Post a Comment